用 redis 实现分布式幂等服务中间件
文章目录
背景
在编程领域,幂等性是指对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。
在分布式系统里,client 调用 server 提供的服务,由于网络环境的复杂性,调用可能有以下几种情况:
- server 收到 client 的请求,client 也收到 server 的响应结果
- client 发出了请求,但 server 未收到,可能是 server 重启、网络超时等原因
- server 发出了响应,但 client 未收到
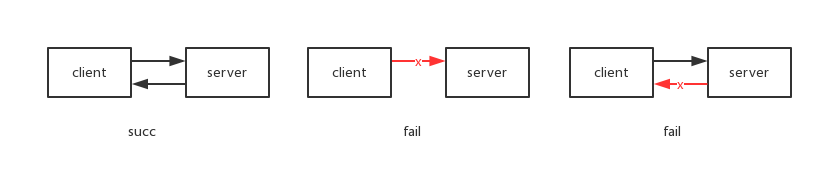
对于后两种情况,client 一般会进行一次重试,这样 server 可能会收到多次重复的请求。对于某些天然就幂等的服务来说,比如对资源的读操作,不管读多少次,资源不会有变化;但对非幂等服务,server 执行一次和重复执行多次,对资源的影响就不确定了。
例如银行扣款服务,用函数表示为 bool withdraw(account_id, amount),client 发起一次调用 withdraw(1001, 10) 请求从帐户 1001 中扣除 10 元,如果发生了上图所示的第 2 种错误,这时候 server 端在帐户里已经完成了扣款,但 client 并不知道,如果重试调用 withdraw(1001, 10) ,server 端又会从 帐户 1001 扣除 10 元,显然这个非幂等的扣款服务并不是 client 想要的。
如果将 client 的一次扣款操作和后续的重试用一个额外的 id 来标识:bool withdraw(id, account_id, amount),server 针对一个 id 的相同请求只执行一次,这样就可以避免上述的问题了。此时扣款服务也是幂等的了。
实现方案
按照上面介绍的幂等的扣款服务的实现思路,抽象出一个通用的中间层,非幂等的服务要改造成幂等的,只需要增加一个额外的 id 参数。服务实现里先根据此 id 去中间层查询服务是否执行过,根据查询结果决定的是否继续后续的业务流程。中间层相当于一个特殊的分布式互斥锁,根据 id 查询的过程相当于对某把锁尝试加锁的操作。锁被锁住后永远不释放(除非锁过期了,这里为了叙述方便简单认为永远不释放)。锁被一个进程锁住后其他进程都无法再加锁,这样就保证了服务是幂等的了。
第一个对互斥锁加锁的进程任务没有执行完就挂掉,锁又是不会释放的,其他进程又无法重复加锁,导致这个失败的任务也不能被其他进程重新执行。为了避免这种情况,将加锁的操作分成 2 步:
- TryAcquire
尝试获取锁,结果有两种情况:- 1.1 拿到了锁(锁转到 TryAcquired 状态),这时候可以执行正常的业务流程,执行完了需要再调用第二步 Confirm 明确锁已被锁住(锁转到 Confirmed 状态),这之后其他进程都拿不到这把锁;
- 1.2 没拿到锁,可能是以下三种情况之一:
- 1.2.1 锁处于 Confirmed 状态,这种情况不应该继续业务流程处理直接返回;
- 1.2.2 锁处于 TryAcquired 状态,但超时时间没到,说明这个时候有其他进程拿到了锁正在进行相应的业务流程,本进程不应该执行相应的业务流程直接返回;
- 1.2.3 锁处于 TryAcquired 状态,但超时时间到了,说明已有其他进程拿到了锁,但很久没有 Confirm ,有可能是执行过程中挂掉了,这时候本进程应该要执行相应的业务流程,然后调用第二步 Confirm 。
- Confirm
将锁置成 Confirmed 状态,表示互斥锁被永久锁住。
锁的状态转换如下所示(expire 为 redis key 过期):
![]()
使用 Redis 实现,key 为互斥锁的标识,value 为锁的状态:
- 0:初始状态* -1:Confirmed 状态
- 其他值:TryAcquired 状态,value 为业务执行截止时间 deadline
server 在增加了保证幂等性的流程图如下(交易表示既定的业务执行流程):
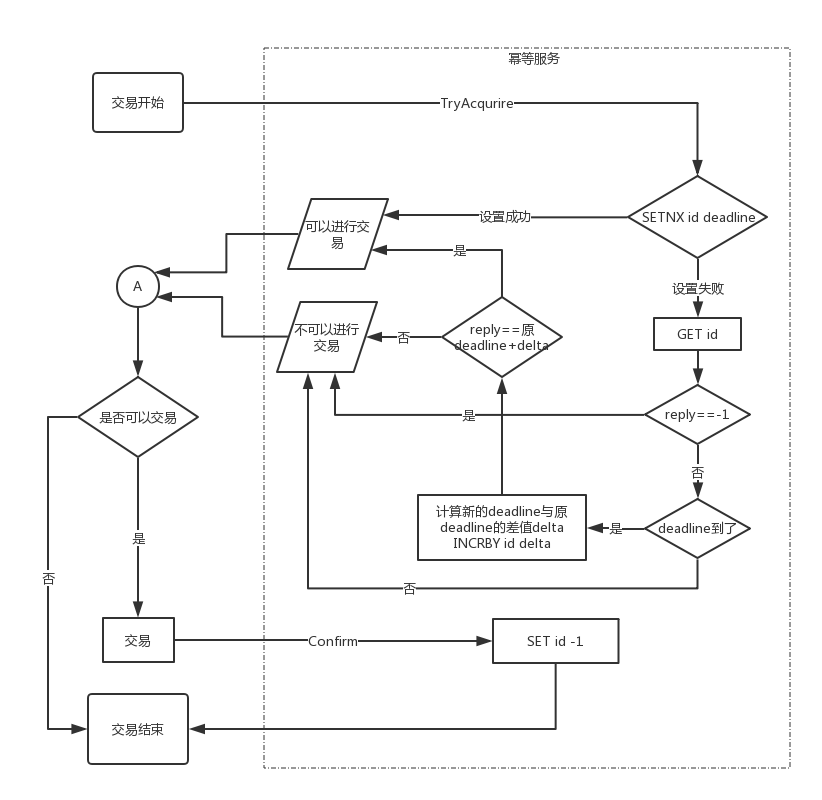
流程图里省略了 redis 错误处理的分支,redis 错误 TryAcquire 直接返回 true 。
TryAcqurie 和 Confirm 实现用伪码描述如下:
|
|
id 的取值
id 由 client 根据具体的业务场景决定,可以本地生成或者是从第三方服务获取,要求需要保证能唯一标识某个业务下的一次交易。server 端将此 id 视为互斥锁的唯一标识。
timeout 的取值
timeout 应该比正常的交易时间大,否则会导致多个进程都能拿到锁不能保证幂等;但是又不能设得太大,否则会导致交易执行失败时要过很久才能重新执行交易。
原子性保证
TryAcquire 和 Confirm 都应该保证原子性,Confirm 只有一个简单的 SET 操作,这个没有问题。TryAcquire 实际上分成两步:1.1 SETNX 和 1.2 GET&SET(不是 redis 是 GETSET 命令)。
上面的伪码中 1.2 GET&SET 的 SET 换成了 INCRBY 并增加了一次返回值比较,相当于使用了乐观锁,所以 GET&SET 的原子性是 OK 的。
下面说明下为什么 1.1 和 1.2 整个过程没有保证原子性也是 OK 的:
最坏的情况下假设进程 a 进入 TryAcquire 执行完了 1.1 然后被操作系统调度出去了,此时进程 b 进入 TryAcquire 执行了整个流程拿到了锁,然后执行了一次交易。这时候进程 a 重新被调度执行,这个时候由于进程 b 更新了 deadline 甚至执行完了 Confirm,进程 a 会在 1.2.1 或 1.2.2 处退出并且不会执行交易,如果走到了 1.2.3 并且拿到了锁说明进程 b 执行交易时挂掉了,这时由进程 a 重新执行交易也是正确的逻辑。
方案的缺陷
这个方案忽略了 redis 异常情况,这种情况下 TryAcquire 总是返回 true ,可能会使交易重复执行不能保证幂等。也可以将 redis 异常返回给调用者,由调用者根据业务场景来决定是否需要重新执行交易。
另外一种情况进程通过 TryAcquire 拿到锁后执行完了交易,但 Confirm 失败(挂掉或者网络问题),这种情况在 dealine 到了后,其他进程仍然可以拿到锁并执行交易,这时候也不能保证幂等。
缺陷的本质是这个轻量级的解决方案无法保证分布式事务的原子性。