并发模型
文章目录
互联网后台的最大特点就是海量请求,如何在有限的资源下尽可能服务更多的请求是后台开发主要的关注点。传统上设计一个高可用高并发的互联网后台主要原则有横向扩展和纵向扩展。横向扩展要求服务尽量无状态依赖,纵向扩展主要是提高单机的吞吐量,比如使用更好的硬件配置。在编程模型的选择上,采样哪种并发模型也会大大影响单机的吞吐量(参考著名的 C10K 问题)。
上古时期的互联网服务
以早期的 web 服务为例,浏览器中地址栏输入网址回车后,发起 HTTP 请求到 web 后台。web 容器(apache)收到请求后,解析请求然后生成浏览器需要的数据(读取静态文件或者启动一个 cgi 进程生成动态内容),最后通过 HTTP 响应返回给浏览器。
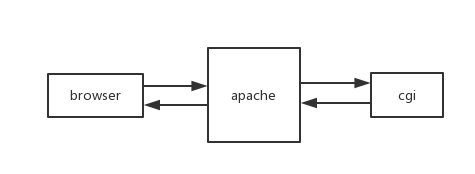
屏蔽掉网络通信息协议,进程间通信等等各种细节,以上例子可以说明一个互联网后台的主要工作:
- 接收网络请求
- 处理业务逻辑生成客户端需要的数据
- 发送网络响应
不管今天的互联网后台如何复杂,如果都归纳成以上这种抽象的话,于是一个原始的互联网后台程序可能是这样:
|
|
多进程
上面的例子中,后台简单的串行服务每个客户端的请求,假设处理每个请求的时候需要 1 秒的话(TPS=1),根据以下系统吞吐量的计算公式可以得到这个原始的单进程后台系统的吞吐量为 1。
吞吐量 = TPS * 并发数
在 TPS 一定的情况下,通过增加进程数可以提高并发数,进而提高整个系统的吞吐量,例如使用 cgi 模式的 apache 服务。但是并发数和进程数不是简单的线性关系。操作系统创建和调度进程需要一定的开销,在进程数达到一定数目情况下,这个开销可能相当可观。
在业务逻辑复杂的情况下,后台服务可能还要涉及到进程间的通信与同步,这些需要通过系统调用操作内核对象介入,也会产生一定的开销。由于每个进程独享一个进程空间,进程内的异常不会影响到其他进程,相对来说,使用多进程方式的并发模型还是比较简单的。
多线程
操作系统发展的早期并没有线程的概念,后来才慢慢发展出线程。作为操作系统调度的基本单位,线程要比进程更轻量,这里不再赘述进程与线程的区别了。由于更小的开销,通过多线程通常可以获得更好的并发数,进而提高整个系统的吞吐量,例如使用 fastcgi 的 apache 服务。
由于多个线程共享一个进程空间,不可避免的引入了资源竞争问题,通常需要通过锁来避免,这也增加了多线程程序的复杂度。通常编写多线程程序对开发者的要求也更高,写过多线程程序的同学应该深有体会。
异步回调
在上述代码中,使用简单的同步阻塞IO,进程/线程顺序处理客户端的请求,处理请求时,进程/线程独占CPU,直到被操作系统切换出去。一个请求处理完成后,才能接着处理下一个请求。通过增加进程/线程数可以提高并发量进而提升整个系统吞吐量。
异步回调是另外一种并发模型,通常使用非阻塞IO,通过事件机制驱动程序的运行。仍以上文中的后台程序为例,如果用这种模型来编程的话,代码可能类似这样:
|
|
虽然实际的代码远比上述示例复杂,但这个示例基本概括了使用异步回调的并发模型时的要点:
- 关注哪些事件及编写处理这些事件的回调函数
- 设置事件监听器不断监听事件然后调用相应回调函数驱动程序运行
从上面的示例代码可以看出,原本处理客户端请求的顺序的过程分散到了多个事件的回调函数里,不容易看出请求的处理流程,编写起来比同步方式复杂,特别是在交互逻辑复杂的场景下,编程复杂性更是成倍增加。
性能比较
在上述的多进程/线程并发模型中,单个进程/线程以同步方式顺序处理客户端请求,通过增加进程/线程数提高并发量进而提升整个系统吞吐量。上述吞吐量的计算公式中可以看出,TPS 是影响系统吞吐量的另一个因子,以下说明使用异步回调的模型如何提高单个进程/线程的 TPS。
一般程序的执行过程可分为 CPU bound 和 I/O bound , CPU bound 表示进程占用 CPU 资源进行各种计算,I/O bound 表示进程占用 I/O 资源处理 I/O 事件(磁盘读写/网络包收发等)。通常一个后台程序处理一个请求时上述两者都有,只是占用时间比例大小不同而已。仍以上文中的例子说明,假设 CPU 为单核,后台处理客户端一个请求时占用 CPU 和 I/O 资源各 0.5 秒(灰色部分为 CPU bound):
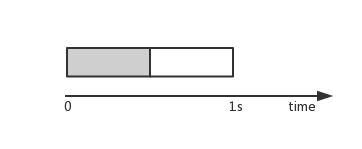
在单进程串行服务的例子里,进程处理完一个请求的 CPU bound 阶段,接着占用 I/O 设备进行网络收发,此时 CPU 是空闲的,但是无法接着处理一下个请求,必须等到这个请求的 I/O 操作也处理完,这就造成的硬件资源的浪费。在上述的多进程/线程并发模型中,一个请求的 CPU bound 阶段完成后转到 I/O bound 阶段,这时候操作系统可以调度另外一个进程继续使用 CPU 。通过这种增加进程/线程的方式,由操作系统来调度多个进程/线程使用 CPU 和 I/O 资源,可以最大限度榨取硬件的潜力。上述在单核 CPU 条件下,忽略操作系统的调度开销,理论上设置 2 个进程/线程,此时单进程/线程的 TPU 为 1 ,并发数为 2 ,系统的吞吐量达到最大值 2 。
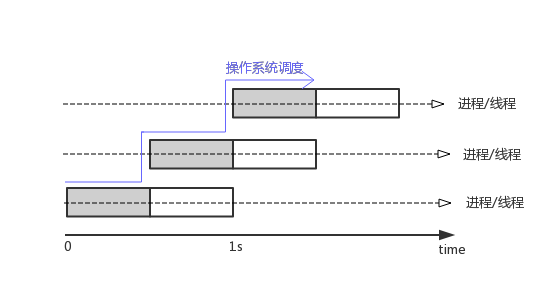
在相同的硬件条件下,使用异步回调的并发模型编程时,每个请求的处理过程在逻辑上实际仍然是一半时间为 CPU bound , 一半时间为 I/O bound ,不同的是由事件来驱动主进程在不同的请求的处理过程中切换。通过下图可以看出,在理想的情况下,单个进程 1 秒内最多能处理2个请求,此时 CPU 利用率达到极限。此时单进程/线程的 TPU 为 2 , 并发数为 1 ,系统的吞吐量达到最大值也是 2 。
如果从请求处理的角度来看,逻辑上每个请求的处理流程都是一样,只不过使用多进程/线程并发的编程模型时,是由操作系统来调度决定处理当前请求时使用的硬件资源(CPU 还是 I/O 设备)。使用异步回调的并发模型时,实际上是用户态程序根据事件在调度。
通过上面的分析可以看出,在硬件资源一定的条件下,忽略操作系统调度进程/线程的开销,理想情况下不管使用哪种并发模型系统能达到的最大吞吐量是一样的。
显然实际情况并非这样,在 C10K 问题的解决方案中也能得到结论,使用异步回调的并发模型性能要优于多进程/线程方式,并且由于现代操作系统中高性能系统调用 epoll()/kqueue() 的出现,这种差异更加明显。
多进程/线程并发模型中,虽然性能一般,但由于同步的编程方式比较符合正常人的思维,编程比较简单。异步回调的并发模型里,编程复杂,但性能较好。在高性能后台开发中,通常会结合上述并发模型的优点,通过多进程/线程提高并发数, 通过异步回调提高 TPU ,最大限度提升系统的吞吐量。
为什么选择 golang
如果即能用同步的编程方式,又能达到异步回调的性能,自然是最完美的方案了。上述的多进程/线程并发模型中,限制系统吞吐量的主要因素是操作系统调用进程/线程的开销。在 C/C++ 的解决方案中 (比如 libco ),通过语言库来实现用户态的线程(通常叫协程或微线程),避免系统级的调度开销。但毕竟只是一个补丁方案,并且由于 C/C++ 的包袱,需要考虑过多的底层细节,使用起来也并不简单。
golang 则在语言层级支持了这个方案。golang 的 goroutine 可以视为用户态线程,并且通过 channel 支持 CSP 模型。golang 的用户态线程与系统级线程可以看成多对多的映射关系,语言运行时负责 goroutine 的调度,大大减少了系统级调度的开销(不能完全避免,在多线程并发模型中,用户态线程与内核线程是一一映射,与之相比,golang 多对多映射模型减少了系统级线程的数量)。
除此之外,golang 的以下特性也是后台开发语言选型时重要的参考因素:
- 多范型语言,支持各种编程范式
- 编译型语言,有较好的执行效率
- 简单精炼的语法,易于上手,开发效率高
- 垃圾回收,避免陷入内存管理细节
- 社区活跃,开源社区有各种优秀的库支持
基于以上原因,使用 golang 进行后台开发时能在开发效率与执行效率上有比较好的平衡,实际上也有越来越多的互联网公司选择 golang 作为后台开发的主力语言。
为什么不选择 golang
用合适的工具解决相应的问题,golang 基本上适合大多数后台开发的场景。在一些例外景中,golang 并不是合适的选择。比较纯 CPU bound 又追求性能的场景,应该选择更底层的语言。至于技术之外的因素,这里就不涉及了。
总结
本文简单介绍了常用的并发模型然后安利了一把 golang 。多进程/线程模型编程相对简单,异步回调模型编程复杂但效率更高。golang 的语言特性结合了两者的优点,用同步的方式编程,又能达到接近异步的性能,再加上有活跃的社区支持,适合用来编写高性能的互联网后台应用。
关于并发模型更多的细节,可以参考《七周七并发模型》。